Latest News
- Clues beginning to emerge on asymtomatic SARS-CoV-2 infection
- Back in November of 2020, during the first wave of the COVID-19 pandemic, I was teaching an in-person microbiology laboratory. One of my students had just been home to see his parents, and they all c…
- Read more
- Could there maybe be better uses of genetics and probiotics?
- Professor Meng Dong and his laboratory have created a probiotic that can metabolize alcohol quickly and maybe prevent some of the adverse effects of alcohol consumption. The scientists cloned a highl…
- Read more
- ChatGPT is not the end of essays in education
- The takeover of AI is upon us! AI can now take all our jobs, is the click-bait premise you hear from the news. While I cannot predict the future, I am dubious that AI will play such a dubious role in…
- Read more
- Fighting infections with infections
- Multi-drug-resistant bacterial infections are becoming more of an issue, with 1.2 million people dying of previously treatable bacterial infections. Scientists are frantically searching for new metho…
- Read more
- A tale of two colleges
- COVID-19 at the University of Wisconsin this fall has been pretty much a non-issue. While we are wearing masks, full in-person teaching is happening on campus. Bars, restaurants, and all other busine…
- Read more
( 12799 Reads)
|Our goal in this section is to help you find the information you can trust. Here you will learn habits that can help you to become and remain an informed citizen. Briefly, you should: read widely, verify references, be aware of data manipulation, know the difference between causation and correlation, identify the shams and flimflams, trust peer-review, consider the source, and be skeptical.
One significant pitfall of the wealth of information available online is that it is easy to fall into like-minded groups that agree with your worldview. You wrap yourself in a cocoon of self-assurance with friends that reinforce what you think and say, rarely challenging your ideas. The cure for this is to read widely. Look at publications and information that may present a point-of-view with which you don’t agree. Exploring other points of view will expose you to varying opinions, but will also help you to practice countering spurious arguments.
A critical part of a search for truth is using credible sources. I pointed above to places to search, but how do you verify the integrity of a source? First, identify the level of the source, primary, secondary, tertiary, or popular press. Remember that primary literature, which presents data generated by the author to support their ideas, is the most trustworthy and it decreases from there. However, any information source can have problems (see the examples at the end of the chapter). So what diminishes the quality of an article?
Do they have citations to support factual claims that they make? If there are none, be suspicious. If they do cite other literature, who do they cite? Do they cite a credible source you trust? Does an established and respected organization publish it? Again, linking to other blog posts doesn’t count for much compared to ideas obtained from the Center for Disease Control and Prevention. Follow a couple of citations from the article you are reading. Do the claims made in the article you are reading match the reference to which they link? If they do not, be skeptical. I have run across writing that cites scholarly articles to support its point of view. However, checking thses citations against the original article reveals that they have nothing to do with it or, in the worst case, actually refute the author’s claims.
Data can lie too
To take liberty with a phrase that was popularized by Mark Twain, “There are lies, damned lies, and statistics.” It is easy to manipulate information and use statistics and graphs in marginal ways to create convincing arguments. Misleading data can be notoriously hard to spot, and it sometimes takes some expertise, but I am going to try to equip you with a few rules that may be able to help.
Sample size and distribution
When presented with a statistic, immediately ask, what is the sample size, and how is the data distributed? All statistics, be they from experiments or surveys, are a collection of observations. The hope is that this sample is a good representation of the observed phenomenon. If you are looking at polls for an upcoming political race, remember that they don’t ask the entire electorate. They try to find a sample that closely represents the whole population. If they do a good job modeling the folks who eventually go out to vote, the poll will be accurate. If their model makes poor estimations of who will vote, they can be wildly off. The presidential election of 2016 was a great example of this. The likely voter screens that almost all pollsters use discounted infrequent voters who came out in higher numbers than expected.
Two of the more important measures of the quality of a data set is the size of the sample and its distribution. In general, the larger the sample, the more accurately it should mimic the entire population under observation. Second, you want a normal distribution. There are complex statistical formulas and ideas behind this, but in simple terms, a normal distribution is where values appear equally above the average and below it. An example you are probably familiar with is the bell curve for grade distributions. When a sample becomes skewed and does not follow a normal distribution, many standard statistical analyses are not possible. For example, imagine you are doing a study of weight gain when consuming the latest bodybuilding supplement, SuperSupp. (By the way, I made that up. Any real or imagined likeness to an actual supplement is coincidental) You put together a test group of 30 bodybuilders to try it to see if they gain muscle mass when they consume it. You also have a control group of 30 bodybuilders who are not taking the supplement. After three months, you measure their change in muscle mass. Here is the data that you generate:
|
Subject |
SuperSupp Group |
Control Group |
Subject |
SuperSupp Group |
Control Group |
|
1 |
-4 |
-2 |
16 |
0 |
-1 |
|
2 |
0 |
-5 |
17 |
0 |
2 |
|
3 |
-2 |
3 |
18 |
2 |
1 |
|
4 |
3 |
0 |
19 |
-1 |
0 |
|
5 |
4 |
3 |
20 |
25 |
-1 |
|
6 |
0 |
-4 |
21 |
-4 |
1 |
|
7 |
19 |
-4 |
22 |
2 |
-2 |
|
8 |
-3 |
5 |
23 |
4 |
4 |
|
9 |
2 |
-5 |
24 |
-4 |
-1 |
|
10 |
-3 |
5 |
25 |
-3 |
5 |
|
11 |
0 |
1 |
26 |
4 |
0 |
|
12 |
0 |
1 |
27 |
-2 |
-5 |
|
13 |
19 |
-4 |
28 |
4 |
0 |
|
14 |
5 |
2 |
29 |
4 |
5 |
|
15 |
5 |
-1 |
30 |
2 |
-3 |
Table 2.1 Comparison of muscle mass gain of SuperSupp users and a control group. A control group and a test group that consumed SuperSupp were observed for 12 weeks. Weight gain was measured at the beginning and the end of the study
If you take the average of these values, you will see that the SuperSupp gained 2.6 kg, and the Control group gained no muscle. If you do a statistical test, called a T-test, you find this difference is significant, having a p-value of 0.06. In this case, the p-value is the probability that the two groups, SuperSupp users and the control group have the same muscle mass gain. A p-value of 1 means that 100% of the time that you perform this test, the two groups would show identical muscle mass gain. A p-value of 0 means that there is no chance they would show the same muscle mass gain. Since 0.06 is very close to 0, there is a 94% chance that the two groups are different, meaning SuperSupp works! Well, not really because there is a problem. Figure 2.1 shows a graph of the data.
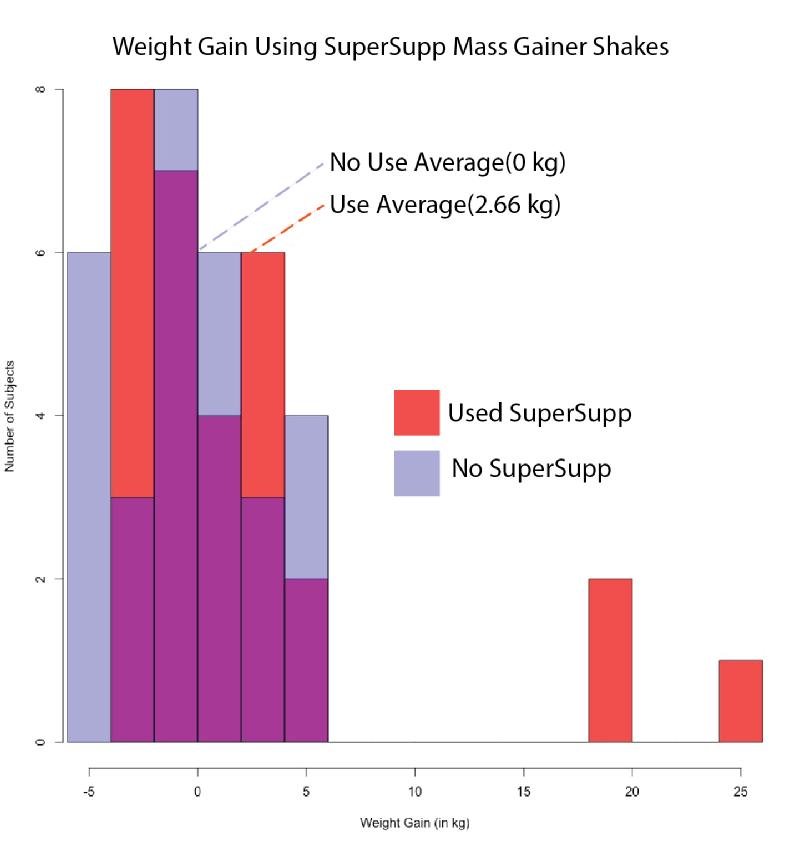
Figure 2.1. Super Supp and Weight Gain. A graph of the data shows the muscle gain of SuperSupp users and a control group.
You can see that the data from the two groups pretty much overlap, but there are three individuals in the SuperSupp group that are far beyond the average and are skewing the data. The distribution of the SuperSupp group is not normal, and you cannot use statistical tests, such as the T-test, that assume normality. Also, the number of test subjects is quite small, a better study, using hundreds of participants, would be much more powerful.
Let’s take a real-world example to drive the point home. Suppose a politician is claiming that if a tax cut bill passes, the average American is going to get a $4,000 tax cut. While this is technically true, the reality is that there is no average American as far as income goes because wealth and income in the United States do not follow a normal distribution. Now before you call me a lefty socialist, watch this video and pay particular attention to the chart that appears at 4:24. Income does not follow a normal distribution and is heavily skewed toward the top earners Therefore a calculation of an average tax cut is unquestionably meaningless. A much better method is to calculate the median income and figure out the tax cut from that value. The median is the point in a number set where half the numbers are below and half are above. For income level, it would mean the income that half the population makes less and half the population makes more. If you do that, you get a much smaller number than the average tax cut.