Latest News
- Clues beginning to emerge on asymtomatic SARS-CoV-2 infection
- Back in November of 2020, during the first wave of the COVID-19 pandemic, I was teaching an in-person microbiology laboratory. One of my students had just been home to see his parents, and they all c…
- Read more
- Could there maybe be better uses of genetics and probiotics?
- Professor Meng Dong and his laboratory have created a probiotic that can metabolize alcohol quickly and maybe prevent some of the adverse effects of alcohol consumption. The scientists cloned a highl…
- Read more
- ChatGPT is not the end of essays in education
- The takeover of AI is upon us! AI can now take all our jobs, is the click-bait premise you hear from the news. While I cannot predict the future, I am dubious that AI will play such a dubious role in…
- Read more
- Fighting infections with infections
- Multi-drug-resistant bacterial infections are becoming more of an issue, with 1.2 million people dying of previously treatable bacterial infections. Scientists are frantically searching for new metho…
- Read more
- A tale of two colleges
- COVID-19 at the University of Wisconsin this fall has been pretty much a non-issue. While we are wearing masks, full in-person teaching is happening on campus. Bars, restaurants, and all other busine…
- Read more
( 52787 Reads)
|Learning Objectives
After reading this section, students will be able to...
- Explain the organizational units of the cell, cytoplasm, ribosomes and nuclear region.
- Describe how enzymes in a pathway can be organized into structures that facilitate their activity.
- Identify the structure of the cytoplasm and explain that most of the metabolic reactions occur in the cytoplasm.
- Explain the roles of RNA in translation.
- Explain the roles of microscopically visible structures in the cell (inclusions, vesicles, and magnetosomes).
For a refresher or introduction to basic chemistry and biochemistry, please read chapter 2. In this chapter, we will look at how this chemistry combines to form major functional units. These units carry out the major business of the cell: growth, replication, feeding, and movement. We will describe the cell from the inside out, starting with the cytoplasm, moving to the membrane, the cell wall, and finally surface structures on microbes. Before we begin, we should describe an important evolutionary hypothesis that will make sense of much of the following details. As you will see, there are a number of curious similarities and differences in the details of cellular structure among Bacteria, Archaea and eukaryotes. In general much of the machinery in a eukaryotic nucleus and in the cytoplasm looks rather a lot like what is present in the archaea. However, the organelles of eukaryotes, such as the mitochondria and chloroplasts, have properties that are much more similar to those of bacteria. How is this possible? One clue comes from observing organisms in nature. Cooperative relationships are ubiquitous between different species, and this is also true in the microbial world. In some instances, these relationships involved close physical contact between their participants, sometimes with one participant engulfing the other. In 1968 Dr. Lynn Margulis extended this observation and proposed that some of the organelles found in eukaryotes, specifically mitochondria and chloroplasts, were originally endosymbionts of their host. Originally these two microbes probably could live independently, but over time, the endosymbiont lost functionality that its host was already providing and then became dependent. Over the years, ample evidence has accumulated to support this exceptional insight.
- Both mitochondria and chloroplasts contain DNA that resembles the chromosomes of bacteria.
- Both organelles are surrounded by two membranes reminiscent of Gram-negative cell wall structure (see below).
- Mitochondria and chloroplasts divide by a method that resembles binary fission.
- Much of the internal structure and biochemistry of the photosynthetic organelle inside chloroplasts is very similar to that observed in cyanobacteria (a photosynthetic microbe).
- The ribosomes of mitochondria and chloroplasts resemble those found in microbes and analysis of the sequence of the 16S rRNA of these ribosomes showed that the organelles are in fact closely related to proteobacteria (mitochondria) and cyanobacteria (chloroplasts) This last bit of proof is very strong evidence substantiating Dr. Margulis's hypothesis.
In summary, it seems clear that the eukaryotic cell was born by merging an archaeal cell with a Gram-negative proteobacteria. Photosynthetic eukaryotes arose from a second endosymbiosis, where the eukaryotic cell engulfed a cyanobacterium. Clearly, eukaryotes, including us, resulted from the cooperation of several single-celled species in the long distant past. In other words, not only do you have bacteria growing on you, you are bacteria. Therefore, what you learn here about the basic workings of a bacterial cell will apply to all cells.
The cytoplasm is the area inside the membrane
The cytoplasm or protoplasm is the portion of the cell that lies within the cytoplasmic membrane. The cytoplasmic matrix consists of substances within this membrane, excluding the genetic material. In most prokaryotes, it appears to be relatively featureless by electron microscope, but all that means is that there are no large structures we can see. In contrast, eukaryotic cells have mitochondria and other visible organelles that exist for different specific functions. Despite this visual simplicity, the prokaryotic cytoplasm is the site of almost all important metabolic functions in the cell.
The cytoplasm has a gel-like consistency, with rather different properties than the simple solutions that we typically make up in the laboratory. This characteristic is because there is surprisingly little free water in the cell. Rather than picturing the cytoplasm as a pool of water with the occasional large molecule floating around, it is better to think of it as a bag of proteins and other macromolecules, each coated with a layer of water, with a modest number of free water molecules bouncing around in between. There is so little free water in the cell that one-third of all water molecules are making hydrophilic contact with the macromolecules in the cell. Given this difference between our lab solutions and the actual nature of the cytoplasm, it is a bit surprising that the biochemical analyses we perform in the lab mimic the behavior observed in the cell.
Enzymes serve as catalysts in the cytoplasm
The cytoplasm is where most metabolism occurs, and we describe the details of these processes in the chapters on metabolism and photosynthesis. However, we mention few general issues concerning enzymes in the cytoplasm here.
Though the cytoplasm appears featureless, there is a significant amount of local organization. A good illustration of this is exemplified by examining the enzymes of DNA replication. Though too small to be seen, the proteins that perform replication are in complex assemblies of many proteins. This assembly is much more efficient than having each protein float around and simply sump into the DNA to perform its function by random chance. For example, DNA gyrase, which unwinds and opens the DNA for copying, has to function in coordination with DNA polymerase, which inserts each new nucleotide in the growing strand. Without this coordination, the DNA would not open up for replication, and the process would simply not occur. It would certainly be possible for the enzymes to float around in the cytoplasm without any interaction in some other processes. Still, it is much more efficient to organize in some fashion. The glycolytic enzymes (enzymes that oxidize sugars for energy) exemplify this type of multi-enzyme complex. One enzyme directly hands over its product to the next enzyme, for which it is the substrate - a sort of molecular assembly line. This coordination of functions is much more efficient because substrate does not accumulate where it should not, and the local substrate concentration for each enzyme is very high.
The cell DNA is organized into a nucleoid
The nucleoid is the cellular region that contains the DNA-protein complex that makes up the chromosome. It is not a set region, as in eukaryotes, with their nuclei but can vary from cell to cell. So what do we know about prokaryotic chromosomes? What is the structure of a typical chromosome?
It is a little awkward to talk about "typical" anything in prokaryotes, since there is always such a large range for any given property. In the case of prokaryotic chromosomes, the smallest known is about 160 kB, while the largest is about 10,000 kB. E. coli is certainly well-studied and might well be considered typical, with strain K12 having a chromosome of 4,639,221 bp containing 4,405 genes. The chromosome for this bacterium is circular, and this is a common arrangement, but there are many species with linear chromosomes. If stretched out, this material would be about 1400 µm long or about 1/16thof an inch. The E. coli cell is about 1-5 µm in length, so it is clear that a remarkable degree of packing is necessary to fit the chromosome inside its tiny host. Figure 3.2 shows the nucleoid of E. coli. The nucleoid occupies half of the bacterial cytoplasm and has a density of 20-50 mg/ml, similar to what is observed for the nucleus of a non-dividing eukaryotic cell. The following description of the nucleoid refers specifically to that of E. coli, but is probably generally similar to that of other prokaryotes.
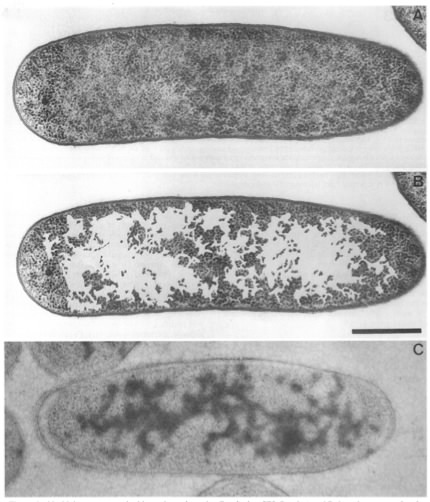
Figure 3.2. Electron micrograph of the nucleoid. The nucleoid as seen in thin sections of growing E. coli. Panels A and B show the same section; in panel B the ribosome-free spaces were enhanced by coloring by hand. Panel C shows a similar cell stained with antibodies specific for DNA. (Source: E. Kellenberger).
The nucleoid is composed of DNA associated with several DNA-binding proteins that help it maintain its structure. The proteins HU, H-NS, and IHF are found in the DNA and help create the nucleoid's structure. HU and H-NS non-specifically bind to DNA, with H-NS serving as the major DNA binding protein. IHF and HU both facilitate the bending of DNA, but IHF does so by binding to specific DNA sites. The nucleoid also contains a large amount of RNA polymerase and RNA, as well as small amounts of many different proteins that regulate the expression of specific genes. These seem not to perform any structural role but reflect the importance of RNA transcription in the nucleoid in growing cells.
The DNA double helix typically has a bit of twisting tension in the opposite direction of the helix ladder (the twists typically "unwind" the left-handed DNA helix). Negative supercoiling, as it is called, is produced by the action of enzymes termed topoisomerases. Figure 3.3 shows the supercoiling of the DNA. This negative supercoiling makes it slightly easier to separate the two strands of the double helix, as must be done to start transcription and replication.
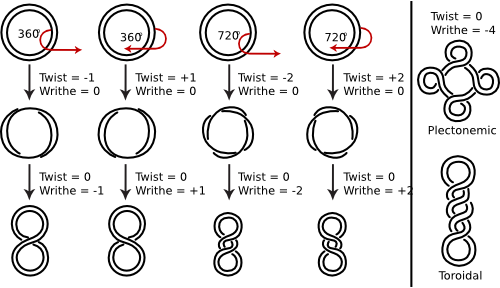
Figure 3.3. Supercoiling of DNA strands. Supercoiling is very difficult to show in a static picture and it is hard to create a cartoon that adequately describes it. Instead consider this: Take a few feet of tubing or a garden hose and hold one end in your left hand. Then with your right hand, rotate the other end along its long axis. Since the tubing/hose is resistant to this twisting, this energy will cause a section of the tubing to form a new structure, a bit like the middle picture above. This "supertwisting" is supercoiling. Now the analogy between tubing and a DNA double-helix is not bad - both objects are able to bend but cannot really rotate much along their long axis, so if one could do the same thing with a piece of DNA, the same supertwisting would result. Of course no one is "holding one end of the DNA" in the cell, but the fact that the DNA is a closed circle has the same effect. In this picture, double-stranded DNA is shown, but for clarity the helical nature of the DNA is not depicted (though it certainly IS helical). Twist refers to the number of helical turns in the DNA and writhe to the number of times the double helix crosses over on itself (these are the supercoils). The bottom two figures shows how the supercoils could be concentrated in a single region or dispersed.
Because supercoiling changes fairly rapidly, studying it in living cells has been challenging. As shown in Figure 3.4,the chromosome is further folded into 50 or so loops of about 100,000 base pairs. These domains supercoil independently, and indeed, even small sections within the same loop can transiently have different degrees of supercoiling. It does appear that supercoiling can affect the expression of genes in a region of the DNA and that gene expression also affects supercoiling. In addition to this rosette morphology, one or several loci of the chromosome are specifically positioned within the cell, and the intervening DNA is kept organized with respect to these landmarks. In fact, you will find specific regions of the chromosome in similar positions in the cell. How this is specifically arranged is species-specific, with different microbes arranging their chromosomes in different ways. For example, E. colikeeps its oriCat the center of the cell and has left and right halves of the chromosome that flow outward from there, eventually meeting at the terminus. Caulobacterspecies, curved rod-shaped microbes, will keep their origin and terminus at opposite poles of the cell.
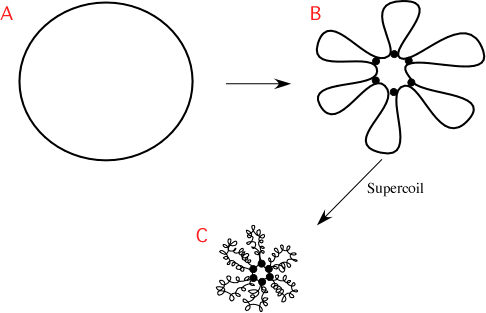
Figure 3.4. Chromosome structural organization. A model of the overall structure of the bacterial chromosome. (A) The unfolded, circular chromosome of E. colidepicted as a single line for simplicity, though of course it is a double-stranded helix. (B) The DNA folded into chromosomal domains by protein-DNA associations. The proteins are depicted as the black circles, interacting with both the DNA and with each other. Six domains are shown, but the actual number for E. coli is about 50. (C) Supercoiling and other interactions cause the chromosome to compact greatly.
Transcription and translation occur on the surface of the nucleoid
So we have told you that the DNA in the cell has a very compact structure because of DNA-binding proteins, but we have also said that this structure is very dynamic because gene transcription is going on all of the time. This paradox creates a complicated situation for the cell that only worsens when it is time to replicate the chromosome. Remember that prokaryotes continue to perform gene expression throughout replication, in contrast to eukaryotes. As you will learn below, transcription and translation are coupled in bacteria - the beginning of the messenger RNA (mRNA), termed the 5' end, is being actively translated while the last portion, termed the 3' end, is still being synthesized (Figure 3.5). Yet, the internal regions of the nucleoid appear to be devoid of ribosomes and non-DNA-binding proteins, suggesting that all transcription and translation must occur on the surface of the nucleoid. Therefore the cell must shift this large tangle of DNA around by some unknown mechanism as gene expression of certain buried sequences is needed. It is a marvel that the whole process of transcription, translation, and replication works at all, especially within the tiny confines of the cell.
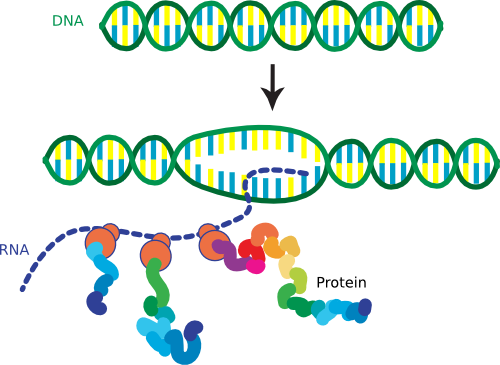
Figure 3.5. The coupling of transcription and translation. In prokaryotes the process of transcription and translation are tightly coupled. This increases the rate at which proteins can be expressed and is one reason that some bacteria can multiply so quickly.
Translation involves messenger RNA
Translation is the process of converting the instructions coded in the DNA into the proteins that carry out the work. The macromolecules that perform this task consist of mRNA, transfer RNA (tRNA), and the ribosome, composed of ribosomal RNA (rRNA) and ribosomal proteins. In brief, this process consists of making an mRNA copy of a region in the DNA that gives directions for the synthesis of protein or proteins. The ribosome then binds the mRNA and translates it into an amino acid sequence. The amino acids necessary for the protein are carried to the ribosome by tRNA that read the information in the mRNA and add the appropriate amino acid to the nascent protein chain. This process is described in much greater detail in the chapter on the central dogma.
We will now examine the structure of the molecules involved in translation, starting with mRNA, where the primary structure is simple - merely unmodified A, G, C and U bases. In almost all prokaryotic mRNAs there is not a great deal of secondary and tertiary structure, since ribosomes are typically translating them and the translating ribosome removes any structure as it moves along the mRNA. What structure there is occurs in the untranslated regions, notably the 5' and 3' ends of the mRNA. One of these structural roles, especially at the 3' end, is to stabilize the mRNA. There are RNases in the cell that degrade the RNA and RNA secondary structure can impede this degradation. The amount of secondary structure is by design, depending upon how long the cell wants the mRNA to last. Due to the need of most prokaryotic cells to respond rapidly to changes in the environment, most mRNAs are not very stable in the cell and degrade rapidly.
Ribosomes are composed of RNA and protein
In contrast to the case with mRNAs, the other RNAs involved in translation, tRNA and rRNA, have very distinct structures. Each rRNA folds into a known secondary structure and has a complex tertiary structure containing many short helical regions and long-range base pair interactions. Interactions between the RNAs and proteins also maintain these structures.
The composition of ribosomes is 62 % RNA and 38 % protein by weight. Two complexes of RNA and protein make up the ribosome, the 30S subunit, and the 50S subunit. (The S stands for Svedberg units, a measure of how fast something sediments in solution. All you need to know for our purposes is that larger molecules sediment faster and have larger Svedberg units. The unit is named after Theodor Svedberg, who won the Nobel Prize in Chemistry in 1926 for his work on suspensions of large molecules and other compounds in solutions.) The 30S subunit is composed of 21 proteins and a single-stranded rRNA molecule of about 1,500 nucleotides, termed the 16S rRNA. The 50S subunit contains 31 proteins and two RNA species, a 5S rRNA of 150 nucleotides and a 23S rRNA of about 2,900 nucleotides. Several of the nucleotides on the 16S and 23S rRNAs have been modified by methylation. These modifications are probably critical to the function of the rRNAs since they always happen in regions conserved through evolution.
The ribosome-associated proteins are positively charged, with a high proportion of lysine and arginine residues. This positive charge facilitates complex formation between the acidic RNA and these basic proteins. Scientists have solved the crystal structure of the entire 70S ribosome, as shown in Figure 3.6. It is remarkable because solving such structures becomes more difficult as the size of the complex increases and the ribosome is huge. We are still trying to understand what the structure tells us about ribosome function. We also know that the ribosome is not static but dynamic, changing shape during a translation cycle.
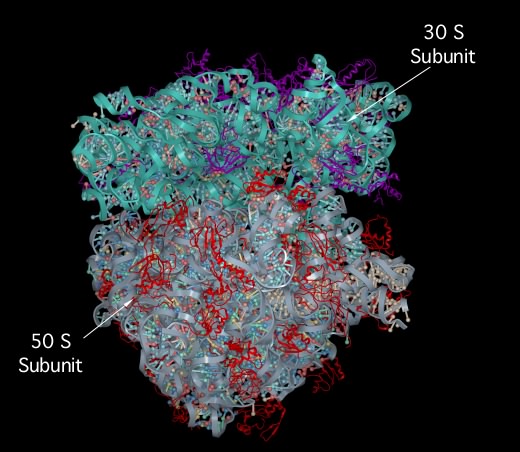
Figure 3.6. The crystal structure of the 70S ribosome.. A molecular model of the 70S ribosome of Thermus thermophilis showing the position of proteins (purple and red ribbon diagrams) and RNA (Gray and cyan ribbons) within the structure. Note the prominence of RNA in the ribosome, which constitutes over 60% of the molecular weight. (Source: adaption from S. Petry et al. 2005. Cell 123:1255-1266)
Transfer RNA is the ferry for amino acids
Transfer RNA (tRNA) is the ferry that transports the amino acids to the ribosome. There are one or more different tRNA molecules for each of the 20 amino acids. Each consists of 70 to 80 nucleotides of single-stranded RNA that is extensively base-paired to form four short helical domains. These structures are commonly represented as a two-dimensional cloverleaf but look more like an "L" in the native three-dimensional structure, as shown in Figure 3.7. The tertiary structures of tRNAs are similar, so the critical features that make each appropriate to a specific amino acid are largely found in the primary structure itself. Enzymes chemically modify many bases in tRNA molecules to help the molecule carry out its function.
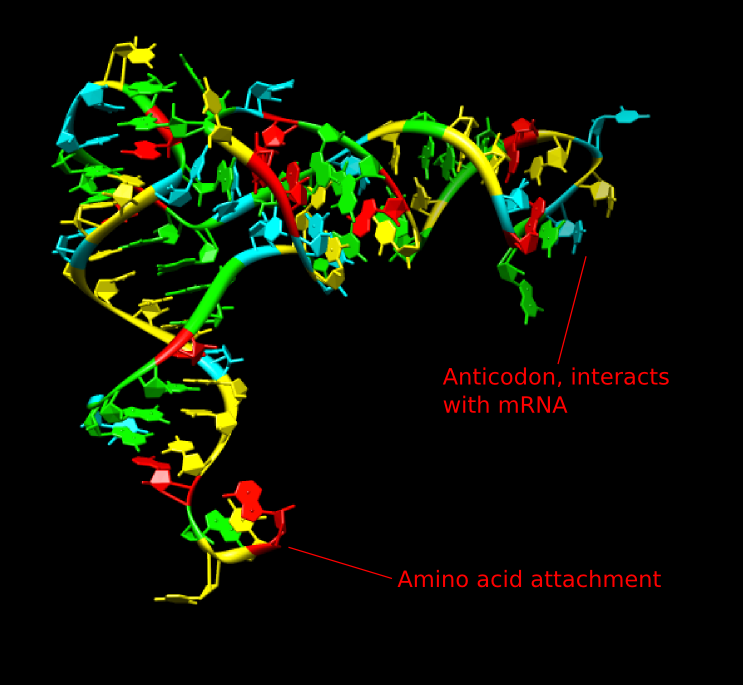
Figure 3.7. The structure of tRNA. The two-dimensional structure of tRNA looks like a cloverleaf, but in the actual three-dimensional form, it has a surprising L-shaped structure as shown. The bottom of the structure as shown here contains the anticodon that interacts with the mRNA. The top right of the structure is where the appropriate amino acid residue is attached by synthetases.
The aminoacyl-tRNA synthetases are the enzymes that add the amino acid to the tRNAs. Figure 3.8 depicts a complex between an aminoacyl tRNA synthetase and tRNA. There is a single synthetase for each amino acid, and it binds each of its appropriate tRNA molecules and charges it with its appropriate amino acid. The synthetases avoid both the wrong tRNAs as well as the wrong amino acids.
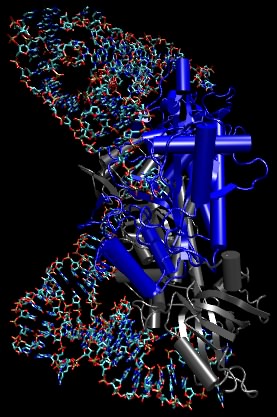
Figure 3.8. The amino acyl-tRNA synthetase complex. A molecular model of aminoacyl tRNA synthetase binding its tRNA. The tRNA is shown as ball-and-stick, while the synthetase is depicted in the ribbon form. In this picture, the anticodon is at the top of the figure and the site of amino acid attachment is at the bottom right. Note that the synthetase does not "sense" the anticodon directly.
One final thought before we move on. Think about the chicken-and-egg conundrum that translation brings up. This whole process has the express purpose of synthesizing proteins, yet it involves proteins at every step. How could these proteins have evolved to serve this function when they are necessary for their synthesis? In other words, how could you synthesize anyprotein until a complete set of translation proteins had evolved? Part of the answer is that primordial translation was probably much simpler, though less accurate and efficient. Perhaps only very few and somewhat general protein functions were required. Alternatively, perhaps early translation used no proteins at all: Some scientists believe that early life employed RNA molecules capable of carrying out necessary enzymatic functions and storing hereditary information. They posit that it was only later that proteins came along and assisted in their synthesis. However, this hypothesis still does not explain how one simultaneously evolved functional proteins and a process for creating them.
Inclusions and other internal structures are found in many prokaryotic cells
There are a few structures in the prokaryotic cytoplasm that are visible by microscopy. Generally, they serve specific purposes in the cell and are often found only in specific cell types or under certain growth conditions. Here we focus on some of the more familiar objects, inclusions, gas vesicles, and magnetosomes.
Inclusions
Inclusions are dense aggregates of specific chemical compounds in the cell. Typically, the aggregated chemical serves as a reservoir of either energy-rich compounds or building blocks for the cell. Forming polymers costs energy, and it may seem wiser for the cell to keep the excess monomers around for when they are needed. The benefit of polymerization is that it decreases the osmotic pressure on the cell, a serious problem as described later. Inclusions often accumulate under laboratory conditions when a cell is grown in the presence of excess nutrients. However, the role of some inclusions is unclear. Growth on rich medium causes their creation, but subsequent starvation in the test tube does not always result in the use of these reserves. This lack of use suggests that these inclusions, at least, are not storage bodies or that we have not found conditions where the cell will use them.
Carbon and energy storage
One of the more common storage inclusions involves poly-β-hydroxyalkanoate(PHA). It is a long polymer of repeating hydrophobic units that can have various carbon chains attached to it. The most common form of this class of polymers is poly-β-hydroxybutyrate, which has a methyl group as the molecule's side chain, as shown in Figure 3.9. The function of PHA in bacteria is as a carbon and energy storage product. Just as we store fat, some bacteria store PHA. Some PHA polymers have plastic-like qualities, and there is some interest in exploiting them as a form of biodegradable plastic.
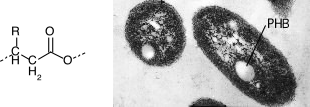
Figure 3.9. Poly-β-hydroxyalkanoate inclusion bodies. The figure shows an electron micrograph of inclusion bodies of poly-β-hydroxyalkanoate inside a cell of a Rhodobacter sphaeroides. The specific chemical here is poly-β-hydroxybutyrate (PHB). In the generalized poly-β-hydroxyalkanoate structure shown at the left, the R group is a methyl in PHB. (Source, Sam Kaplan, University of Texas - Houston Medical School)
Glycogen is another common carbon and energy storage product. Humans also synthesize and utilize glycogen, which is a polymer of repeating glucose units.
Phosphate granules and sulfur globules
Given the opportunity, many organisms accumulate granules containing long phosphate chains since this is often a limiting nutrient in the environment. These polyphosphate polymers, also called volutin, form visible granules in some microbes. These granules are readily stained by many basic dyes such as toluidine blue and turn reddish violet in color. These inclusions are often called metachromatic granules because they become visible by "metachromasy" (a color change). Polyphosphate is found in all known cells (eukaryotes, bacteria and archaea) and appears to serve many important roles.
- It serves as a phosphate reservoir
- It is an alternative substrate in place of ATP when phosphorylating sugars during catabolism.
- It is a chelator for divalent cations
- It can be a buffer under alkaline stress
- It is an important factor for DNA uptake.
- Finally, phosphate polymers are important regulators in response to stress
Figure 3.10 depicts another visible structure, termed a sulfur globule, which is present in various bacteria capable of oxidizing reduced sulfur compounds such as hydrogen sulfide and thiosulfate. Oxidation of these compounds is linked either to energy metabolism or photosynthesis. Oxidation of sulfide initially yields elemental sulfur, which accumulates in globules inside or outside the cell. If the bacterium exhausts the sulfide in the area, it may further oxidize the sulfur to sulfate.
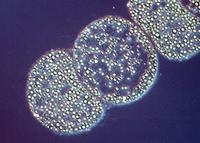
Figure 3.10. Sulfur globules. Sulfur globules found in Thiomargarita namibiensis. This large microbe (100 to 750 µm in size) is found in Walvis Bay off the coast of Namibia. (Source: copyright Max Planck Institute for Marine Microbiology, Bremen, Germany)
Gas vesicles
Figure 3.11 shows an example of gas vesicles, also known as gas vacuoles, that are found in cyanobacteria. Cyanobacteria are photosynthetic and live in lakes and oceans. In these environments, the cyanobacteria use gas vesicles to control their position in the water column to obtain the optimum amount of light and nutrients.
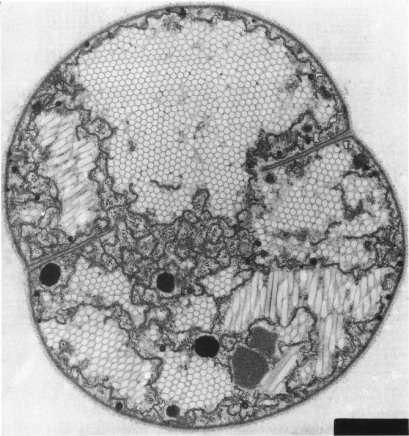
Figure 3.11. Gas vesicles. The hexagonal forms inside the cytoplasm of this cyanobacterium are the gas vesicles. These actively dividing cells are Microscystissp.(Source: A. E. Walsby, 1994. Microbiol. Rev. 58:94-144)
Gas vesicles are often aggregates of hollow cylindrical structures composed of rigid proteins. They are impermeable to water, but permeable to gas. The amount of gas in the vesicle is under the control of the microorganism. The release of gas from the cell causes the bacteria to fall in the water column while filling the vesicle with gas causes the cells to rise.
Magnetosomes
Magnetosomes are intracellular crystals of iron magnetite (Fe3O4) that impart a permanent magnetic dipole to prokaryotic cells that have them. They allow these microbes to orient themselves in a magnetic field. This process does not appear to involve any special machinery besides the magnetosome. Each microbe can be thought of as having a tiny magnet that responds to the magnetic field in the environment. These magnetosomes allow the microbes to follow the magnetic field of the earth. Some species of magnetotactic bacteria have the following behavior. In the northern hemisphere, magnetotactic bacteria swim north along the magnetic field, while in the southern hemisphere, they swim south. Because of the inclination of the earth's magnetic field, this causes the microbes to swim downward. Many microbes containing magnetosomes are aquatic organisms that do not grow well in atmospheric concentrations of oxygen. They move away from the oxygen higher up in the water column by detecting the magnetic field and swimming downward.
A special membrane surrounds magnetosomes that confine the magnetite to a defined area. The membrane likely plays a role in precipitating the iron as Fe3O4 in the developing magnetosome. Magnetosomes can be square, rectangular or even spike-shaped.
Key Takeaways
- The cytoplasm is that area inside the membrane and has a gel-like consistency.
- While there are no visible structures in the cytoplasm in prokaryotes, it is still highly organized. As an example, the nucleoid of the cell, containing the chromosome, is bound by proteins and supercoiled to tightly pack the DNA into the cell.
- Translation occurs at the ribosome and converts the recipe of the protein, encoded in DNA, and mRNA into protein.
- This process also involves another RNA, tRNA, as an adapter.
- The cell cytoplasm does contains some visible structures, called inclusions. These structures function as nutrient storage (PHA, sulfur and phosphorus globules), buoyancy (gas vesicles), and sensing the earth's magnetic field (magnetosomes).
Quickcheck 3-2
Warning, you must be logged in to be able to have your exam graded. Answer the questions below and if you are a registered user of the site you will see a Grade Exam button. Click it to have your exam graded.