Latest News
- Clues beginning to emerge on asymtomatic SARS-CoV-2 infection
- Back in November of 2020, during the first wave of the COVID-19 pandemic, I was teaching an in-person microbiology laboratory. One of my students had just been home to see his parents, and they all c…
- Read more
- Could there maybe be better uses of genetics and probiotics?
- Professor Meng Dong and his laboratory have created a probiotic that can metabolize alcohol quickly and maybe prevent some of the adverse effects of alcohol consumption. The scientists cloned a highl…
- Read more
- ChatGPT is not the end of essays in education
- The takeover of AI is upon us! AI can now take all our jobs, is the click-bait premise you hear from the news. While I cannot predict the future, I am dubious that AI will play such a dubious role in…
- Read more
- Fighting infections with infections
- Multi-drug-resistant bacterial infections are becoming more of an issue, with 1.2 million people dying of previously treatable bacterial infections. Scientists are frantically searching for new metho…
- Read more
- A tale of two colleges
- COVID-19 at the University of Wisconsin this fall has been pretty much a non-issue. While we are wearing masks, full in-person teaching is happening on campus. Bars, restaurants, and all other busine…
- Read more
( 44978 Reads)
|Learning Objectives
After reading this section, students will be able to...
- Describe why the cell makes polymers and the important polymers of the cell.
- Explain the size and structure of sugars
- Explain how sugars monomers are put together to make polymers.
- Explain the chemical and structural differences between DNA and RNA.
Monomers and Polymers
Living systems are made of organic molecules, and the cell has settled on just a few types of molecules to make up the majority of its structures: sugars, nucleic acids, amino acids and lipids. It is somewhat shocking that the list is so short, but it demonstrates the elegance of the whole system.
Monomers are all well and good, but cells are much larger than the molecular scale. How do they do it? The cellular machinery links together these single molecular units into long chains of monomers, called polymers. Polymers make up the bulk of what a cell is, dictating its structure and function. Proteins are polymers of amino acids and they drive the cell's chemical reactions or serve as parts of important structures. Starch is a polymer of glucose, and polysaccharides are polymers of sugars that serve in the cell wall, the cell membrane, and as storage products. DNA is a polymer of nucleic acids and is the library that stores the recipes for making an organism.
For polymers made up of more than one monomer, there are several important implications. How each polymer behaves is dictated by the order in which the monomers appear in the polymer sequence. Each specific combination of monomers will create a unique polymer that has a specific structure and function. Changing any one of the monomers in the polymer might change the properties of the polymer. These ideas are especially true for proteins.
A major point here is the economy that this affords to a cell. Instead of needing the ability to fashion several large custom-designed molecules to carry out services within the cell, only a relatively small set of monomers needs to be made. The cell then assembles these to form polymers. This significant efficiency makes organisms very scalable, to borrow a computing term, allowing the construction of microbes only a millionth of a meter in size to blue whales measuring more than 24.5 meters. We will now look at the structure of important monomers in the cell, and the polymers that are made from them.
Sugars are common in the cell
Sugars serve three basic purposes in the cell: as carbon and energy sources, as reservoirs of carbon and energy, and as parts of cellular structures. Large amounts of energy can be extracted from sugars by processes referred to as catabolism, as discussed in the metabolism chapter. This high energy content may explain why many microorganisms prefer sugars if given a choice of energy sources. The term carbohydrate is often used to refer to sugars because their chemical formula can be broken down into [C(H2 O)] x where x is any number greater than three.
Sugar Monomers
Single sugar molecules are typically 3 to 7 carbons long and are termed monosaccharides. Figure 2.13 shows that each carbon on the sugar molecule is decorated with a hydroxyl group (OH) except for one carbon that forms a carbonyl group (C=O). If the carbonyl group is at the end of the molecule, it forms an aldehyde; if the carbonyl group is in the middle of the molecule, it forms a ketone. All sugars can exist as linear molecules in solution. Those greater than five carbons long can also circularize with the carbonyl group attacking a hydroxyl on one of the other carbons. The circular sugar contains 5 to 7 members in the ring, with one of the members being oxygen. Glucose, fructose, and ribose are some of the more common sugars found in the cell.
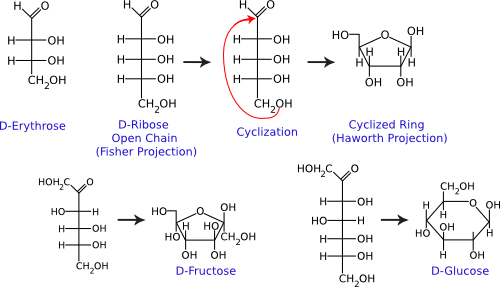
Figure 2.13. Common monosaccharides. The structures of some important monosaccharides are shown. These often serve as building blocks for major structures in the cell, such as the cell wall and the genome. Both the linear and circular forms are shown.
Sugar Polymers
Sugars readily polymerize: the combination of two sugars is called a disaccharide, while the combination of three is called a trisaccharide, and polymers of greater than three sugars are referred to as polysaccharides. Sugars are connected by α or β linkages. If the hydrogen is pointing up, it is an α linkage, and if the hydrogen is pointing down, it is a β linkage, as shown in Figure 2.14. This distinction may seem trivial, but it greatly influences the properties of the molecule. For example, starch is a polymer of glucose linked by α-1,4 bonds. Starch is also water-soluble and can serve as a food source for many organisms. In contrast, cellulose, also containing glucose but linked by β-1,4 bonds, is insoluble in water and is not as readily degraded by most microbes. Polysaccharides might contain only one type of sugar monomer or many, sometimes in repeating units.

Figure 2.14. Common disaccharides, trisaccharides and polysaccharides. Sugars can be linked together to form more complex polymers. Lactose is a common sugar in milk, while maltose is found in many grains. Starch found in potatoes and other vegetables is a long polymer of glucose units. A common form of starch contains 20% amylose and 80% amylopectin.
Polymers of sugars can serve as storage products for the cell. The breakdown of sugar can yield a huge amount of energy, which means that they are terrific molecules for effectively storing energy for later utilization. Starch and glycogen are two examples of sugar polymers that store energy. Polysaccharides also serve as structural components of many different molecules in the cell, including nucleic acids and the cell wall.
Nucleic acids store information and process it
Deoxyribonucleic acid (DNA) and ribonucleic acid (RNA) are involved in information storage and processing. DNA serves as the cell's hereditary information, while RNA converts that information into functional products, such as proteins. Nucleic acids are long polymers of only four nucleotides : adenine, guanine, cytosine, and thymine or uracil. Thymine is in DNA, while uracil is in RNA. Figure 2.15 lists the structure of the five nucleotides found in nucleic acids.
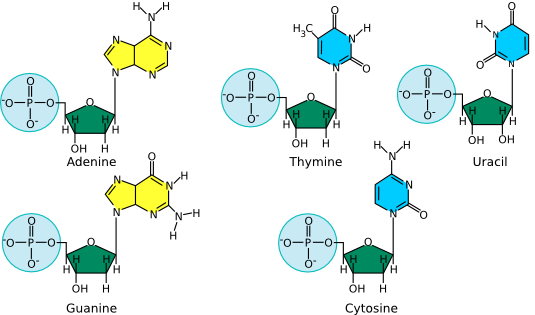
Figure 2.15. The structure of nucleotides. The nucleotides for adenosine (A), guanine (G), cytosine (C ) and thymine (T) as found in DNA are shown. The first three are also found in RNA, but when incorporated into that polymer, the associated sugar has two hydroxyls, as shown in the model of uracil (U). Uracil is the RNA equivalent of the DNA nucleotide thymine.
The nucleotide structure can be broken down into two parts: the sugar-phosphate backbone and the base. All nucleotides share the sugar-phosphate backbone, while the base distinguishes each type of nucleotide. Linking these monomer units together using a 5'-oxygen on the phosphate and the 3'-hydroxyl group on the sugar forms the nucleotide polymer, as shown in Figure 2.16. Many thousands of DNA nucleotides string together to form genes and chromosomes.
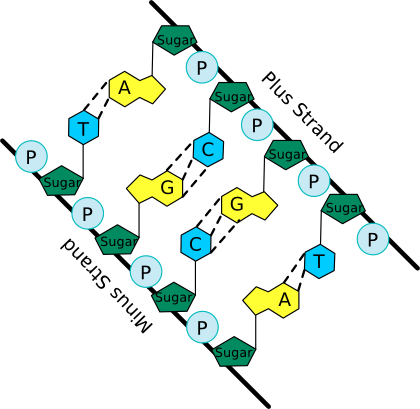
Figure 2.16. A schematic of the nucleic acid polymer. In this picture the bases of the two anti-parallel (having their 5' to 3' linkages running in opposite direction) strands of a DNA double helix are shown. Note the sugar-phosphate backbone from which the bases extend and pair with matching bases from the other strand. The dashed lines show hydrogen bonds between the base pairs.
The bases of the four nucleotides are different, but there is also a pattern. Adenine (A) and guanine (G) are purines, and therefore have a distinctive two-ring structure; they differ in the chemical groups attached to the rings. Likewise, cytosine (C), thymine (T) and uracil (U) are all pyrimidines and share a single-ringed structure, but also differ in their attached groups. Not surprisingly, as these extra chemical groups distinguish the different purines and pyrimidines structurally, they are also responsible for their important functional differences.
The bases in a nucleic acid polymer are capable of forming hydrogen bonds with neighboring bases on a second strand of nucleic acid, a process termed base pairing. However, there are rules to this association. Adenine can form two hydrogen bonds with thymine (or uracil), and cytosine can base pair with guanine, forming three hydrogen bonds. Some of these bonds require the extra chemical groups mentioned above. Suppose two single strands of nucleic acid have sequences that can base pair along the polymer (such sequences are sometimes said to complement). In that case, they will generate a long double-stranded polymer with a staircase topology, as shown in Figure 2.17. This structure is termed a double helix since two strands form the molecule, and it spirals around an axis in a regular pattern. Such a reaction between two complementary DNA strands is spontaneous. If you mix two complementary single strands of nucleic acid in a test tube at a reasonable temperature, pH and salt concentration, they will find each other and anneal to form a double-stranded polymer.
Figure 2.17. The Double Helix. Note how the two nucleic acid strands spiral around each other in a regular repeating pattern. There are 10 bases per turn of the double helix. Bases pair with one another in the center of the helix cylinder and form what some have likened to a spiral staircase. The above figure can be rotated by clicking on the arrows.
Secondary and Tertiary DNA Structures
DNA almost always exists in cells as a double-stranded structure of complementing strands. It happens that this double-stranded form is rather stable. Students often assume that the stability is due to the hydrogen bonding between the bases, but this is not the case (the bases would form hydrogen bonds just as well to water). Instead, it is largely due to the interaction between adjacent base pairs along the helix, which is termed base stacking. Finally, the larger organization of the DNA strands with respect to each other, termed the tertiary structure, is also fairly similar in all DNA molecules. One implication is that proteins that want to distinguish between different DNA molecules must do so by reading different primary structure sequences by interacting with the outer surface of the base pairs, as shown in Figure 2.18.
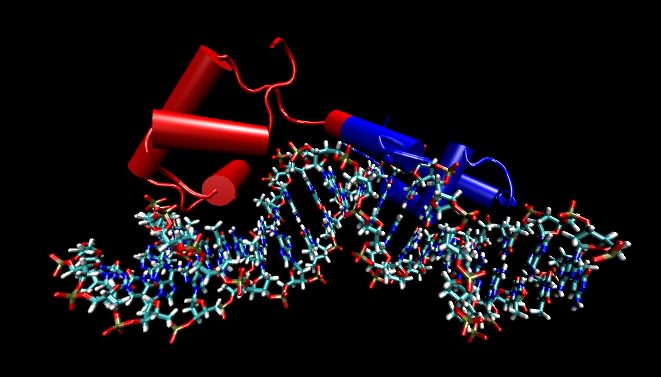
Figure 2.18. A molecular model of the lac repressor. The repressor binding to its recognition sequence. Any DNA-binding protein that recognize specific DNA sequences must make specific contacts with that recognition sequence by reading the pattern of bases in the DNA. These proteins do this by making very specific contacts between themselves and those atoms on DNA that are different in the different bases. In this figure, the DNA helix is shown by the ball-and-stick figure running along the bottom and the protein is depicted by cylinders (which refer to alpha helices) and other "squiggles" (which refer to any other structure in the protein). The point of the figure are that the DNA is not opened up and that the recognition regions of the proteins are very often α helices that lay parallel with or perpendicular to the DNA helix. Not shown are the side chains of the amino acids that actual make the specific contacts with the DNA. In this and subsequent molecular figures, of three different displays will be shown: ball and stick, which shows all atoms larger than hydrogen; ribbon models, in which a ribbon that runs along the carbon backbone of the protein is displayed; and space-filling models, where the actual atomic surface of the molecule is shown. Sometimes, as in this figure, the ribbon form is modified slightly by showing cylinders for alpha helices instead of an actual helix. Most of the structures shown in this text are the product of X-ray crystallography, which essentially displays the position of every atom (larger than hydrogen) in a molecule. Increasingly all biological questions are being thought about in terms of these structures at the atomic scale.
Structures of RNA
In composition and therefore primary structure, RNA is similar to DNA, except that uracil (U) takes the place of thymine in the molecule, and the ribose unit on each sugar contains an additional hydroxyl group. However, most RNA in cells exists as single-stranded molecules and not a complex of two different strands as with DNA. Now, if complementary base sequences are present in an RNA molecule, it can fold back upon itself and base pair so that many RNA molecules have at least some double-stranded regions. However, this bending and folding means that RNA molecules typically have much more complicated tertiary structures than DNA. Both the single-stranded loops and the double-stranded stems are critical for the function of most RNA molecules. Many are involved in creating physical structures, such as ribosomes, that are involved in processing information. The other general class of RNAs are messenger RNAs, which represent a version of the DNA primary structure suitable for translation into protein.
Key Takeaways
- Sugars store carbon and energy and are part of cellular structures.
- Sugars in biological systems are 3 to 7 carbons and contain a carbonyl group.
- Sugars can be monomers or polymers of 2, 3 or more sugars.
- DNA and RNA are composed of two parts, the sugar phosphate backbone and nucleotide bases.
- The bases in DNA are purines (adenine and guanine) and pyrimidines (cytosine and thymine). RNA contains the same bases, except uracil is substituted for thymine and they contain an extra hydroxyl at the 2' carbon.
- DNA polymers can be thousands to millions of base pairs long. RNA polymers are hundreds to thousands of bases long.
- RNA is single-stranded. DNA is double-stranded and forms a double helix in the cell.
- RNA molecules have significant secondary and tertiary structure that is important in their functions.
Quickcheck 2-5
Warning, you must be logged in to be able to have your exam graded. Answer the questions below and if you are a registered user of the site you will see a Grade Exam button. Click it to have your exam graded.